Data and Modeling
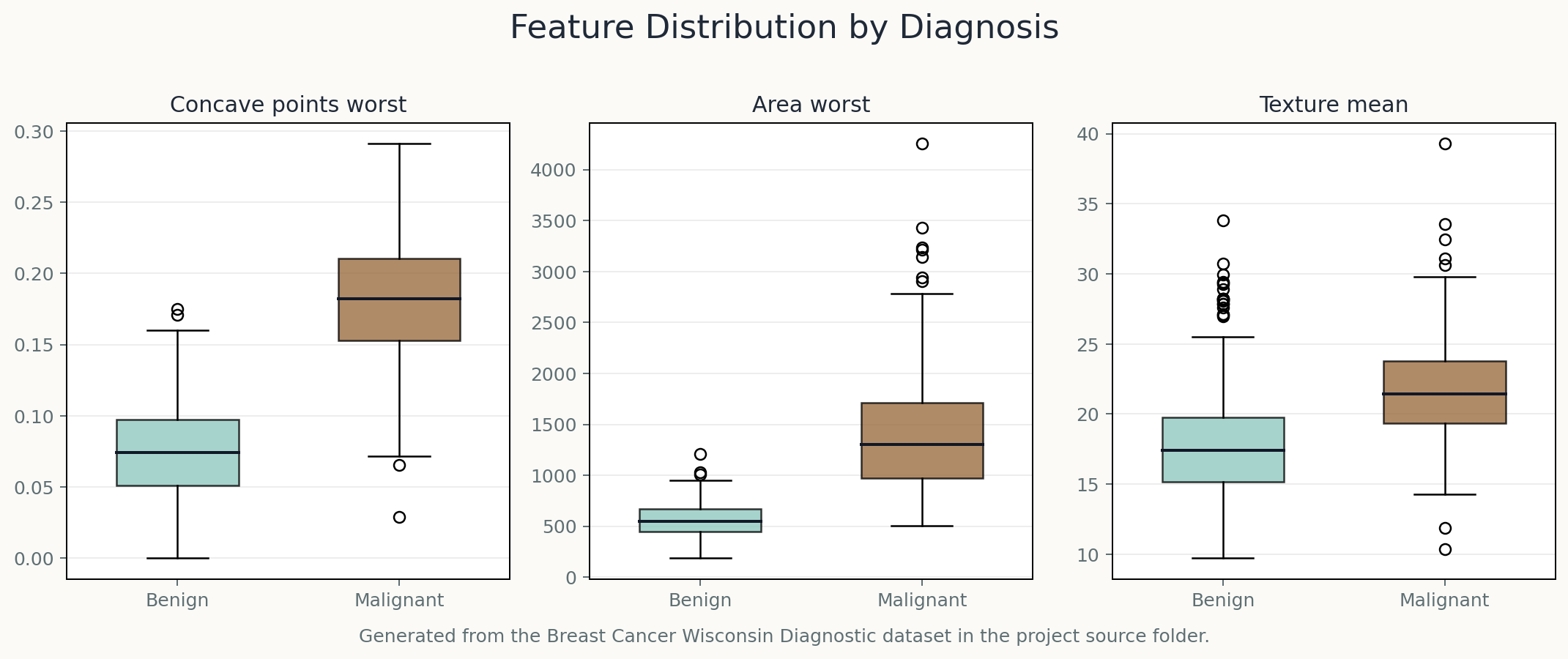
The project uses the Breast Cancer Wisconsin Diagnostic dataset from Kaggle, containing 569 samples with cellular nuclei measurements such as radius, texture, perimeter, area, and concavity.
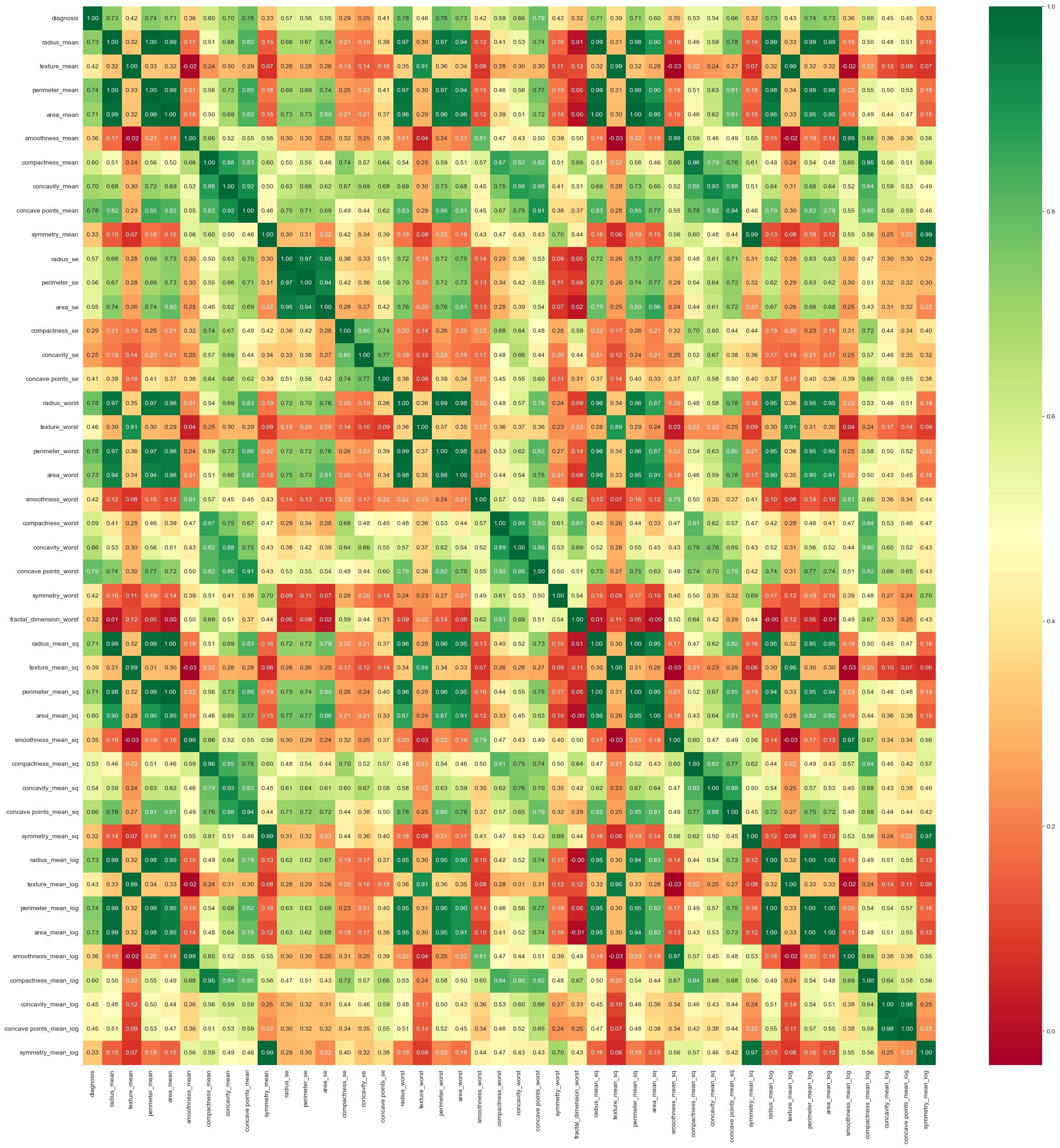
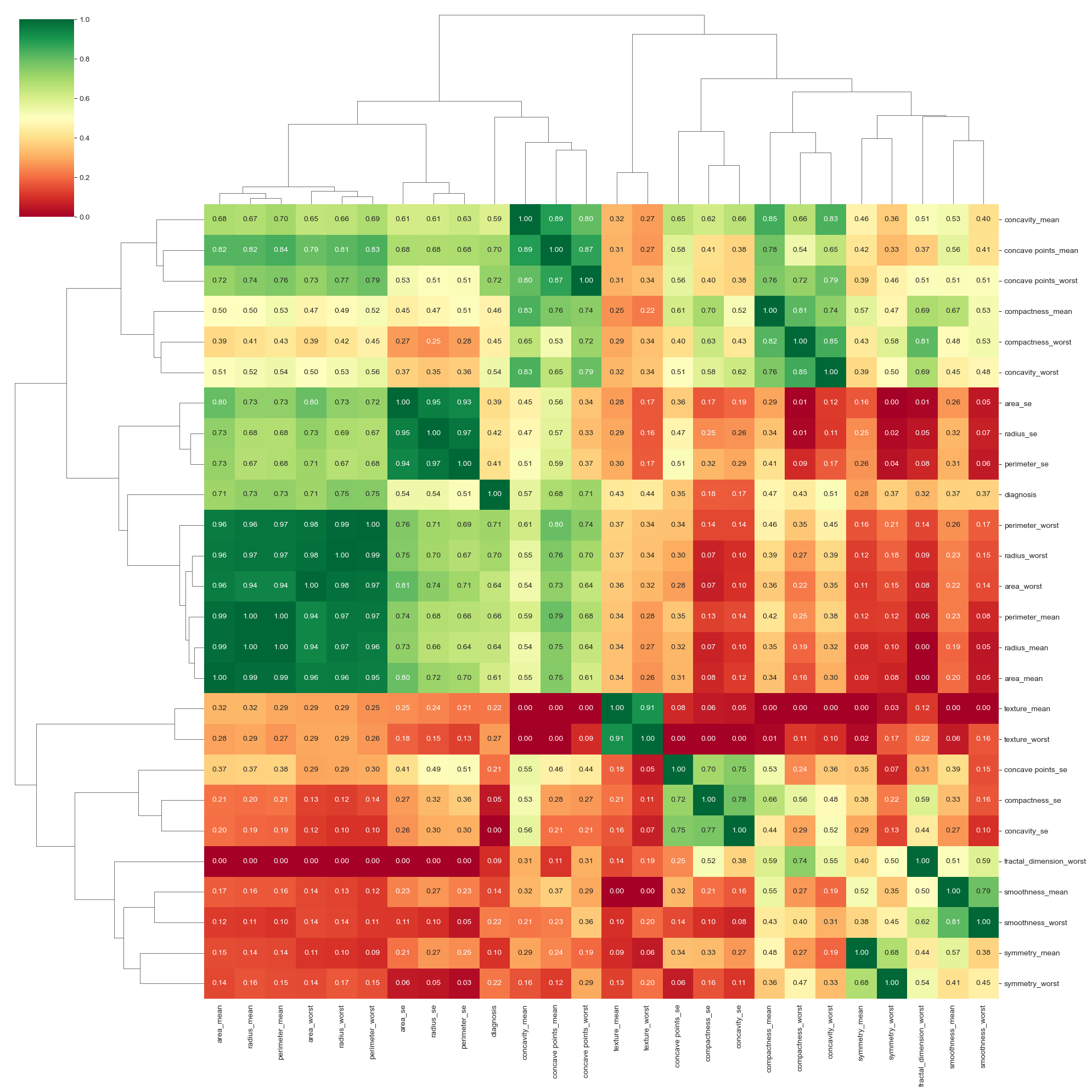
Low-correlation features were removed, transformed variants were explored, and models including KNN, SVM, Random Forest, Decision Trees, and neural networks were compared.
Key Result
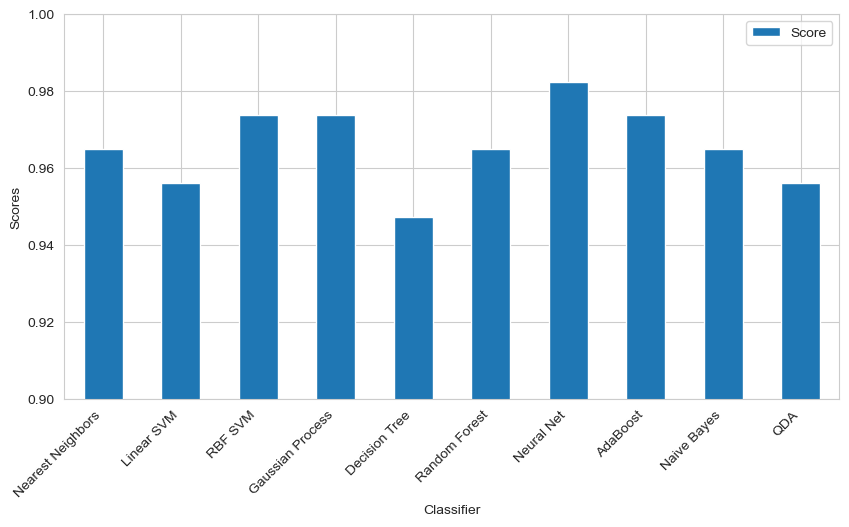
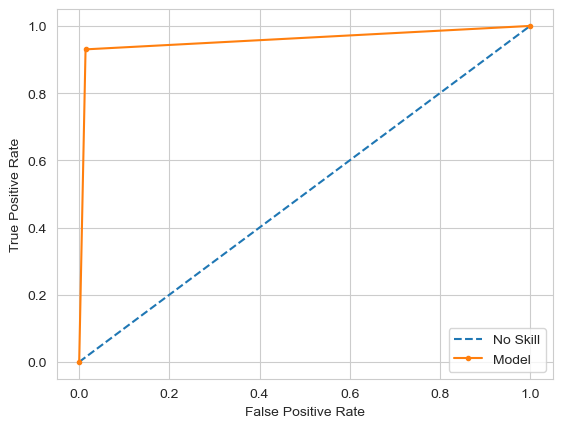
The notebook reports a strongest held-out accuracy of 0.982, with ROC AUC output around 0.967 to 0.977 across saved runs. Classical methods such as Random Forest and KNN remained competitive, which made model comparison more useful than a single-model claim.
Concave points, area-related variables, and texture emerged as important signals for distinguishing malignant and benign samples.