License Plate Recognition using Computer Vision and OCR
An Automatic License Plate Recognition pipeline that combines object detection and optical character recognition to locate vehicle plates and extract text from real-world imagery.
Detect license plates across different framing, lighting, and background conditions.
Extract alphanumeric plate text from detected regions with a practical OCR workflow.
Build a modular pipeline that separates detection, cropping, preprocessing, and recognition.
Use saved result files to review confidence, exact matches, and failure cases honestly.
Data and Inputs
The project uses 433 labeled vehicle images from public license-plate datasets, plus saved model outputs in CSV form. The source material includes sample inputs, preprocessing-output visuals, confidence summaries, and prediction-review tables.
The page intentionally excludes private keys and vendor-specific notebook configuration. The portfolio focuses on the pipeline, outputs, and evaluation framing.
Pipeline
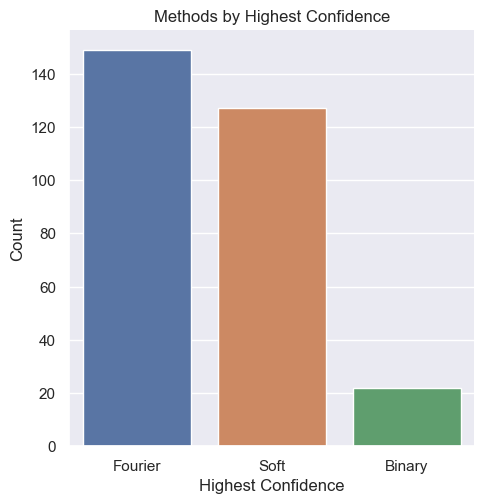
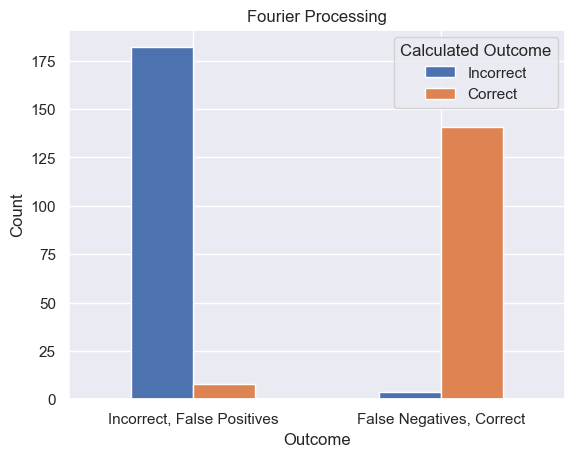
The workflow separates detection, cropping, image preprocessing, OCR, and review. Fourier, soft-threshold, and binary preprocessing variants were compared so OCR quality could be debugged in context rather than treated as one opaque end-to-end result.
This structure makes the system easier to improve because a bad read can be traced to localization, contrast, preprocessing, character recognition, or post-processing.
Evaluation and Output Review
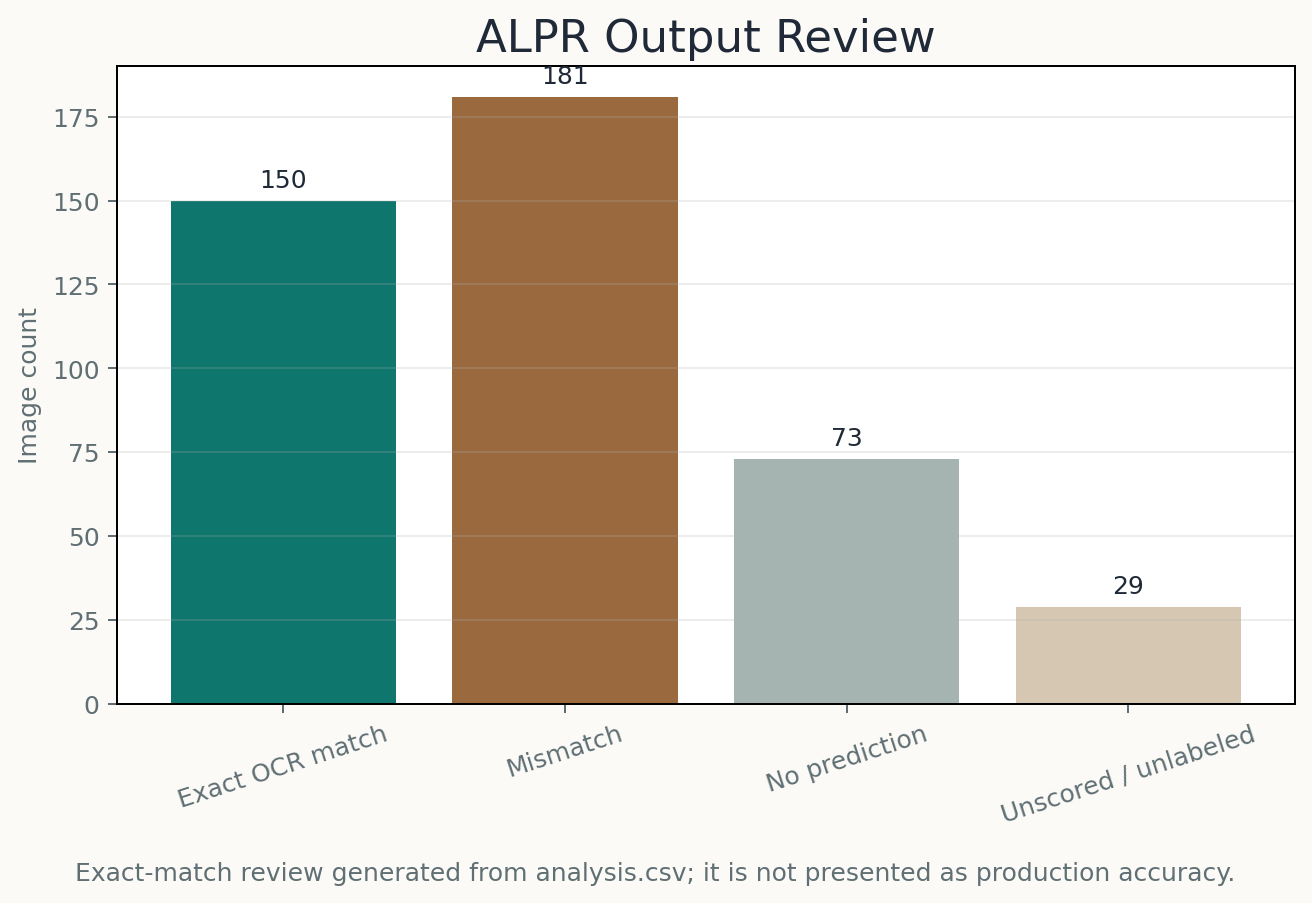
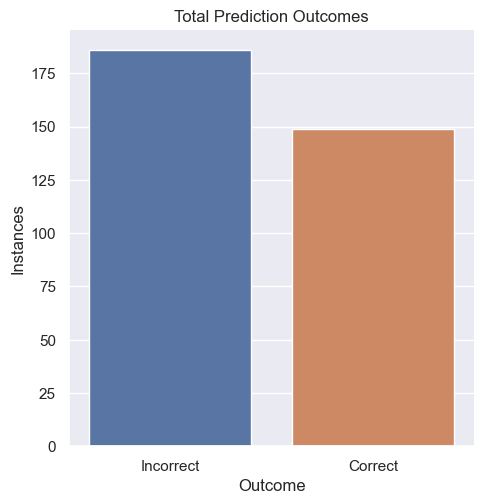
The saved analysis file includes 360 rows with final predictions. Among 331 rows with both a normalized label and a normalized prediction, 150 were exact OCR matches. I present that as an audit result rather than production accuracy because dataset quality, plate validity, and OCR post-processing all affect the number.
The most useful project evidence is the error analysis: high confidence did not always mean a correct full plate, which is a realistic ALPR failure mode.
Limitations and Next Steps
Plates vary in size, angle, contrast, background, and formatting.
OCR accuracy drops quickly when detection crops are noisy or low contrast.
End-to-end performance depends on the interaction between detection and text extraction.
A stronger next version would add plate-format validation, character-level edit distance, more robust crop filtering, and separate detection metrics.
What It Shows
This is a strong applied computer-vision case study because it deals with an imperfect real-world problem rather than idealized input data.
The project demonstrates practical judgment around localization, preprocessing, OCR, and model-evaluation tradeoffs.
Visual Evidence
Conceptual pipeline diagram based on the notebook workflow.Generated exact-match audit from the saved analysis CSV.One exact-match example and one failure case from the source image set.Saved project visualization summarizing prediction outcomes.Saved confidence-score review from project outputs.Preprocessing-output evidence from the Fourier method experiment.